
An Example Investigation
Contents
An Example Investigation¶
This section goes through a data-driven investigation that illustrates common techniques in the Data Scientist’s toolkit: assessing the dataset, formulating a question, joining new data to improve an answer, assessing the applicability of a potential answer beyond the dataset, and due diligence on the validity of each step in the reasoning.
The code in this section is hidden to keep the focus on the data and reasoning. The techniques (and code) used in this section are covered in Part I of this book.
San Diego City Salaries¶
The dataset at hand includes a list of all San Diego city employee salaries for the year of 2017. This includes employee names and job titles, as well as the components of their total pay during that year.
SD Employee Salaries: background research¶
Why try to understand this dataset?
Such a profile could inform 3rd party workplace programs.
Journalists might search for salary anomalies.
Auditors may want actionable advice on fair employment practices.
Are the earning of these employees fair?
Before formulating goals and questions, an initial look is useful understand the data by building a profile of San Diego city employees.
An initial look: what to keep in mind¶
The data, along with a brief description, is available from Transparent California salary website.
Some questions to keep in mind while looking at the dataset:
What columns are required for potential questions that might be asked?
Which columns have the relevant information?
Does that information likely reflect real-life salaries or are there mistakes in the data?
Are the data in the table self-consistent?
salary_path = os.path.join('data', 'san-diego-2017.csv')
salaries = pd.read_csv(salary_path)
salaries.reset_index(drop=True)
| Employee Name | Job Title | Base Pay | Overtime Pay | Other Pay | Benefits | Total Pay | Total Pay & Benefits | Year | Notes | Agency | Status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | David Xxxx | Fire Battalion Chief | 81917.0 | 172590.0 | 68870.00 | 5194.0 | 323377.0 | 328571.0 | 2017 | NaN | San Diego | FT |
| 1 | Glen Xxxx | Fire Captain | 85904.0 | 120682.0 | 99408.00 | 10107.0 | 305994.0 | 316101.0 | 2017 | NaN | San Diego | FT |
| 2 | Scott Xxxx | Chief Operating Officer | 255000.0 | 0.0 | 31164.00 | 22688.0 | 286164.0 | 308852.0 | 2017 | NaN | San Diego | FT |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 12490 | Stephen Xxxx | Council Rep 2 A | 0.0 | 0.0 | 8.00 | 0.0 | 8.0 | 8.0 | 2017 | NaN | San Diego | PT |
| 12491 | Tania Xxxx | Sr Mgmt Anlyst | 0.0 | 0.0 | 8.00 | 0.0 | 8.0 | 8.0 | 2017 | NaN | San Diego | PT |
| 12492 | Brian Xxxx | Police Officer | 0.0 | 0.0 | 3.00 | 0.0 | 3.0 | 3.0 | 2017 | NaN | San Diego | PT |
12493 rows × 12 columns
Aside on privacy and ethics¶
This dataset contains the full names of city employees; these names correspond to real people. Such information is called PII, which stands for personally identifiable information. In many cases it is illegal to improperly disclose PII. In this case public employees are public figures and it’s not against the law to disclose their names.
However, there is a difference between what is legal and what is ethical. In this case, the difference between ‘public record’ and ‘searchable record’ may have very different impact on someone’s life. Public record exists to give people who want to know a small amount of relevant information the ability to do so. Collecting all public records for a single person in one place creates an intimate picture of that person’s life that may easily cross into invasion of privacy.
The takeaway: there are people behind each data point, and those people’s data should not be needlessly propagated! In this case, the last names of the employees have been blanked out, even though it’s not legally necessary to do so.
Basic description of employee pay¶
The table below contains a basic of description of employee pay. What does typical pay look like? Are there questions about data reliability?
salaries.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Base Pay | 12493.0 | 48843.853918 | 29377.449188 | 0.0 | 28888.0 | 49254.0 | 68952.0 | 255000.0 |
| Overtime Pay | 12493.0 | 6573.031858 | 15308.455700 | -623.0 | 0.0 | 393.0 | 5408.0 | 196978.0 |
| Benefits | 12493.0 | 8667.754983 | 6456.089561 | -29.0 | 2785.0 | 8420.0 | 13485.0 | 36030.0 |
| Total Pay | 12493.0 | 64984.971024 | 41812.990357 | 3.0 | 36430.0 | 61452.0 | 91400.0 | 323377.0 |
| Total Pay & Benefits | 12493.0 | 73652.726007 | 45761.462637 | 3.0 | 44788.0 | 71264.0 | 103131.0 | 328571.0 |
| Year | 12493.0 | 2017.000000 | 0.000000 | 2017.0 | 2017.0 | 2017.0 | 2017.0 | 2017.0 |
| Notes | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
A few of the questions raised by this table of statistics are:
What are the negative payments? Near zero salaries?
Where did the “Other Pay” column go?
Are the salaries in the ‘max’ column real?
This dataset only contains one year!
These descriptive statistics hide a lot of information about the data. However, that over-simplification makes the dataset more understandable. These questions are a starting point for focusing a detailed investigation into the dataset and how well it represents the reality being analyzed.
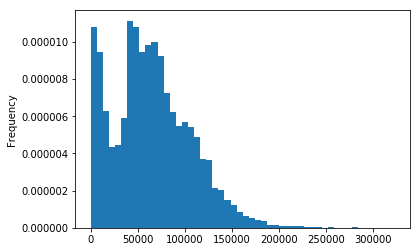
Empirical Distribution of Salaries¶
As employee total pay is the primary attribute of focus, it makes sense to understand how it varies across the entire population of employees. Plotting the empirical distribution of salaries raises two observations:
The distribution is ‘bimodal’ and is likely comprised of two distributions.
The salaries have a skew to the right, which is typical for a quantity that can only be non-negative.
salaries['Total Pay'].plot(kind='hist', bins=50, density=True, title='distribution of Total Salaries');
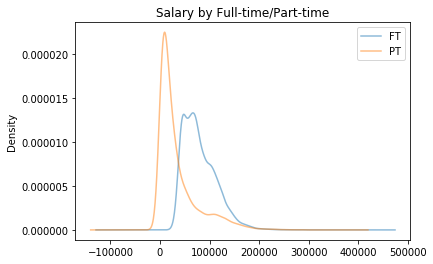
A reasonable guess for the bimodal nature of the distribution of salaries is the employment status. One would expect salaries to vary significantly based on whether an employee works Part-time versus Full-time. Splitting the population up by job status reveals two distributions:
The part-time jobs tend to have lower salaries, closer to 0,
The full-time jobs tends to have salaries centered around 80,000 USD.
bystatus = salaries.groupby('Status')
bystatus['Total Pay'].plot(kind='kde', alpha=0.5, title='Salary by Full-time/Part-time')
plt.legend(bystatus.groups);
salaries = salaries[['Employee Name', 'Job Title', 'Total Pay', 'Status']].copy()
Do women earn similar pay to their contemporaries?¶
With a general assessment of the data finished, a more pointed questions about the data can be pursued. In this case: do employees of different genders have similar pay?
However, this dataset doesn’t contain information on the gender of employees. The dataset does have the first names of employees, which contains imperfect information about gender. A reasonable approach is to find a dataset that contains information about correspondences between names and gender.
In this case, the Social Security Administration publishes a “baby names” dataset that does exactly this.
SSA names dataset¶
The Social Security Administration compiles a list of all names on social security applications in a given year, whether the applicant identified as Male or Female. This list can then be used to label the most likely gender of the employees using their first names.
from glob import glob
import os
names_path = os.path.join('data', 'names.csv')
names = pd.read_csv(names_path)
names.head()
| firstname | gender | count | year | |
|---|---|---|---|---|
| 0 | Emily | F | 25956 | 2000 |
| 1 | Hannah | F | 23082 | 2000 |
| 2 | Madison | F | 19968 | 2000 |
| 3 | Ashley | F | 17997 | 2000 |
| 4 | Sarah | F | 17702 | 2000 |
Basic check of names:¶
There are a number of details to attend to in SSA dataset:
Many names identify to both genders (gender-neutral names).
Most names occur only a few times per year (most names are rare).
A few names make up most the applications.
Notice, the name “Madison” is mostly identified as female, though there are consistently a few males with that name as well:
# look at a single name
names[names['firstname'] == 'Madison'].sort_values(by='year', ascending=False)
| firstname | gender | count | year | |
|---|---|---|---|---|
| 1887827 | Madison | M | 36 | 2018 |
| 1866629 | Madison | F | 7036 | 2018 |
| 161087 | Madison | F | 7875 | 2017 |
| ... | ... | ... | ... | ... |
| 1932167 | Madison | M | 27 | 1882 |
| 1843222 | Madison | M | 28 | 1881 |
| 1841285 | Madison | M | 22 | 1880 |
178 rows × 4 columns
Approach to joining gender:¶
Create a table of distinct names with the proportion of applications on which that name identifies as female.
That is, for each name \(N\), compute:
Join this table to the salaries dataset.
First, creating the table of counts of gender for each name over every year:
# Counts by gender
cnts_by_gender = names.pivot_table(
index='firstname',
columns=['gender'],
values='count',
aggfunc='sum',
fill_value=0
)
names_idx = ['Aaron', 'Maria', 'Dakota', 'Ashley', 'Avery', 'Paris']
cnts_by_gender.loc[names_idx, :]
| gender | F | M |
|---|---|---|
| firstname | ||
| Aaron | 4307 | 581330 |
| Maria | 546026 | 4237 |
| Dakota | 33204 | 86089 |
| Ashley | 846120 | 15668 |
| Avery | 125883 | 55646 |
| Paris | 28841 | 8812 |
From the total counts in the above table, calculate the proportion of a given name that’s identified as female. If this number is greater than 0.5, then the name is likely associated to female; otherwise the name mostly associates to male.
# proportion of a given name that's identified female
prop_female = (cnts_by_gender['F'] / cnts_by_gender.sum(axis=1))
genders = (
prop_female.rename('proportion of a given name that\'s identified as female').to_frame()
.assign(**{'gender':
prop_female.apply(lambda x:'F' if x > 0.5 else 'M').rename('prop_female').to_frame()
}))
genders.loc[names_idx]
Add a given name column to salaries and join names¶
This table of names and their most likely gender attaches a ‘most likely gender’ to the employees in the salaries dataset. This identification is approximate and doesn’t reflect the actual gender with which the employees identify.
# Add firstname column
salaries.loc[:, 'firstname'] = salaries['Employee Name'].str.split().apply(lambda x:x[0])
# join gender
salaries_with_gender = salaries.merge(genders.reset_index(), on='firstname', how='left')
salaries_with_gender.sample(5).reset_index(drop=True)
| Employee Name | Job Title | Total Pay | Status | firstname | proportion of a given name that's identified as female | gender | |
|---|---|---|---|---|---|---|---|
| 0 | Leonardo Xxxx | Library Clerk | 43336.0 | FT | Leonardo | 0.001915 | M |
| 1 | Reina Xxxx | Accountant 3 | 77461.0 | FT | Reina | 1.000000 | F |
| 2 | La Xxxx | Info Sys Anlyst 3 | 72983.0 | FT | La | 0.824943 | F |
| 3 | Montserrat Xxxx | Pool Guard 1 | 8476.0 | PT | Montserrat | 1.000000 | F |
| 4 | Serena Xxxx | Program Manager | 122884.0 | FT | Serena | 0.999616 | F |
Do women earn similar pay to their contemporaries?¶
With a most likely gender attached to the salaries dataset, the salaries can now be described by gender:
pd.concat([
salaries_with_gender.groupby('gender')['Total Pay'].describe().T,
salaries_with_gender['Total Pay'].describe().rename('All')
], axis=1)
| F | M | All | |
|---|---|---|---|
| count | 4165.000000 | 7907.000000 | 12493.000000 |
| mean | 53970.997119 | 71226.907550 | 64984.971024 |
| std | 36251.189372 | 43419.913446 | 41812.990357 |
| min | 8.000000 | 3.000000 | 3.000000 |
| 25% | 25853.000000 | 41557.500000 | 36430.000000 |
| 50% | 50789.000000 | 67874.000000 | 61452.000000 |
| 75% | 75128.000000 | 100689.000000 | 91400.000000 |
| max | 237512.000000 | 323377.000000 | 323377.000000 |
There is clearly a large difference in salaries between the males and females! This observation brings up a variety of questions:
Is this difference the result of some sort of true unfairness, or perhaps the difference is just due to chance?
If the difference isn’t due to chance, why does it exist?
Use a hypothesis test¶
Another way of phrasing the question “Is this difference the result of some sort of true unfairness, or perhaps the difference is just due to chance?” is as
Can women’s median pay be explained as a random subset of the population of city of SD salaries?
If so, the salary of women doesn’t significantly differ from the population; otherwise, some other mechanism is needed to explain the difference!
Hypothesis tests answer these sorts of questions. In particular, such a question can be simulated:
Random subsets of employees are drawn from the dataset, of the same size as the number of female employees,
The median salary of each of these random groups is calculated,
The observed salary of female employees is compared to the simulated ‘randomly drawn’ median salaries. Finally, one asks if the observed, real-life salary was just as likely drawn from a random subset of employees. If so, then the observed difference may have occurred due to chance; otherwise, something else is going on!
The plot below illustrates the results of this simulation:
The blue distribution represents the median salaries of these ‘randomly formed groups’.
The orange dot represents the real-life median female salary.
It seems unlikely this difference is due to chance!
# size of sample is number of women:
n_female = (salaries_with_gender['gender'] == 'F').sum()
# calculate observed
female_median = salaries_with_gender.loc[salaries_with_gender['gender'] == 'F']['Total Pay'].median()
# simulate 1000 draws from the population of size n_female
medians = []
for _ in np.arange(1000):
median = salaries_with_gender.sample(n_female)['Total Pay'].median()
medians.append(median)
title='Median salary of randomly chosen groups from population'
pd.Series(medians).plot(kind='hist', title=title);
plt.plot([female_median], [0], marker='o', markersize=10)
plt.legend(['Observed Median Salary of Women', 'Median Salaries of Random Groups']);
Truism of data science¶
Now that the question of differences in the salaries of genders is answered, a truism of data science rears its head: answering one question always raises a dozen more.
First, are the results correct?
Is dataset error-free and representative (or error-free enough)?
Is the name-to-gender assignment correct (enough)?
What biases might have been introduced when joining the dataset of names to salaries?
Are the results applicable outside of 2017? outside of San Diego?
Second, why are the results what they are?
Is the disparity correlated to pay-type? job status? job type?
What is the cause of the disparity?
The sections below approach each of these questions, giving a feel for what’s involved in answering them.
Is the dataset representative?¶
Look up the “transparent California” and verify this dataset is a census (everyone).
Is “Total Pay” the most appropriate field to use?
Cross-reference independent counts of city of San Diego employees to assess the salary data.
What is the population of interest? Is it San Diego employees in 2017, or something more broad?
Is the name-to-gender assignment correct?¶
How many names are borderline male/female?
Does it make sense to incorporate name usage from all years in the dataset? (1880-2017?)
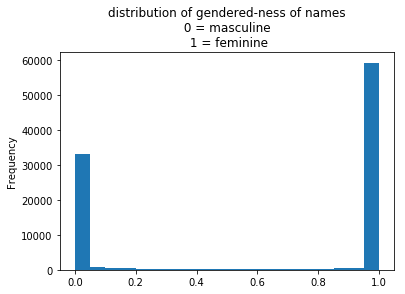
The plot below shows the distribution of ‘proportions of names being female.’
The bar near 0 are counts of names that are almost entirely male.
The bar near 1 are counts of names that are almost entirely female.
There are very few names in the middle that are gender-neutral.
However, each unit plotted is a distinct name; the proportions hide the number of people with each name. What if the most popular name in the country is gender-neutral? This distribution doesn’t reveal this property and is an example of what’s called an Ecological Fallacy (see the chapter on grouping and aggregation).
What’s more appropriate is to look at this distribution of confidence among the dataset of employees.
title = 'distribution of gendered-ness of names\n 0 = masculine \n 1 = feminine'
prop_female.plot(kind='hist', bins=20, title=title);
Assessment of the join?¶
Are there names in the salary dataset that aren’t in the SSA dataset?
Who might not be in the SSA dataset?
Might these names be biased toward certain salaries?
Does the salary dataset have a disproportionately large portion of gender-neutral names.
Is it better to use a subset of the SSA dataset (e.g. by state? by year?)
Do the gender of names typically vary by geography or over time?
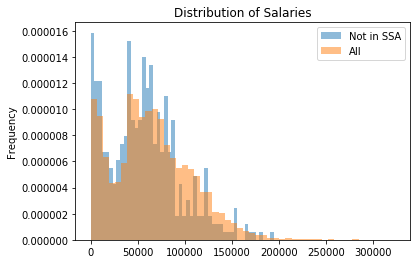
The proportion of employees not in the SSA data is 3.5%, which is fairly small, but may affect the results. These individuals should be investigated more closely; a look at the employees with a gender assigned versus those that didn’t appear in the SSA names dataset reveals some bias (see table below).
Perhaps those that didn’t appear in the names dataset have lower salaries because they belong to an uncommon ethnic group (e.g. an immigrant group)? Such populations would likely work in jobs that earn lower salaries. One could further clean up these missing genders by incorporating the demographic information from immigration data.
These problems centered around bias from missing data are covered in the ‘Missing Data’ chapter of the book.
# proportion of employees not in SSA dataset
# salaries_with_gender['gender'].isnull().mean()
# Description of total pay by joined vs not joined
(
salaries_with_gender
.assign(joined=salaries_with_gender['gender'].notnull())
.groupby('joined')['Total Pay']
.describe()
.T
)
| joined | False | True |
|---|---|---|
| count | 421.000000 | 12072.000000 |
| mean | 56714.684086 | 65273.389745 |
| std | 38445.038529 | 41897.581538 |
| ... | ... | ... |
| 50% | 54966.000000 | 61653.000000 |
| 75% | 78376.000000 | 91895.000000 |
| max | 194920.000000 | 323377.000000 |
8 rows × 2 columns
nonjoins = salaries_with_gender.loc[salaries_with_gender['gender'].isnull()]
title = 'Distribution of Salaries'
nonjoins['Total Pay'].plot(kind='hist', bins=50, alpha=0.5, density=True, sharex=True)
salaries_with_gender['Total Pay'].plot(kind='hist', bins=50, alpha=0.5, density=True, sharex=True, title=title)
plt.legend(['Not in SSA','All']);
Why does pay disparity exist?¶
Is the pay disparity correlated to another field? job status? job type? Is the proportion of women in a job type correlated to pay? One approach might ask if women earn similar salaries as men for a given job type.
Below, a few job types are isolated for investigation. For example, those who work in ‘Fire’ related fields tend to be male and make high salaries:
# select jobs with word 'fire' in them
firejobs = salaries_with_gender.loc[salaries_with_gender['Job Title'].str.contains('Fire')]
firejobs.sample(5)
| Employee Name | Job Title | Total Pay | Status | firstname | proportion of a given name that's identified as female | gender | |
|---|---|---|---|---|---|---|---|
| 342 | Michael Xxxx | Fire Engineer | 150291.0 | PT | Michael | 0.004957 | M |
| 555 | Dustin Xxxx | Fire Fighter 2 | 134974.0 | FT | Dustin | 0.006679 | M |
| 12027 | Chase Xxxx | Fire Fighter 2 | 3900.0 | PT | Chase | 0.021086 | M |
| 5718 | Nick Xxxx | Fire Dispatch Supv | 62799.0 | FT | Nick | 0.002659 | M |
| 2627 | Dave Xxxx | Fire Engineer | 91446.0 | FT | Dave | 0.001780 | M |
The proportion of fire-related jobs held by women is only 8.8%, yet fire-related jobs make significantly more than the overall median pay of 61,000USD per year:
# Proportion of fire-related jobs held by women
#(firejobs['gender'] == 'F').mean()
# Pay Statistics for fire-related jobs
firejobs['Total Pay'].describe()
count 1017.000000
mean 110967.646018
std 49678.113970
...
50% 112568.000000
75% 141502.000000
max 323377.000000
Name: Total Pay, Length: 8, dtype: float64
On the other hand, those with library-related jobs tend to be female and make lower-than-average salaries:
# select jobs with library related jobs
libjobs = salaries_with_gender.loc[salaries_with_gender['Job Title'].str.contains('Librar')]
libjobs.sample(5)
| Employee Name | Job Title | Total Pay | Status | firstname | proportion of a given name that's identified as female | gender | |
|---|---|---|---|---|---|---|---|
| 5955 | Patricia Xxxx | Librarian 2 | 63320.0 | FT | Patricia | 0.996853 | F |
| 10363 | Joseph Xxxx | Library Aide | 17777.0 | PT | Joseph | 0.004060 | M |
| 11194 | Jaqueline Xxxx | Library Aide | 10189.0 | PT | Jaqueline | 0.998469 | F |
| 8706 | Alexis Xxxx | Library Clerk | 39696.0 | FT | Alexis | 0.841756 | F |
| 8430 | Steven Xxxx | Library Clerk | 43056.0 | FT | Steven | 0.003469 | M |
The proportion of library-related jobs held by women is 64%, yet library related jobs make significantly less than the overall median salary:
# Proportion of library-related jobs held by women
#(libjobs['gender'] == 'F').mean()
# Pay Statistics for fire-related jobs
libjobs['Total Pay'].describe()
count 651.000000
mean 30383.377880
std 23236.318495
min 23.000000
25% 10598.500000
50% 26952.000000
75% 43566.000000
max 167269.000000
Name: Total Pay, dtype: float64
What is the cause of the disparity?¶
Now that the picture of employee salaries is better understood the next steps all consist of domain more research:
Research historical gender preferences across jobs
list possibilities and formulate hypothesis for a cause,
find data capable of describing these possibilities,
use a natural experiment to argue causality.