
Understanding Data: Introduction
Contents
Understanding Data: Introduction¶
What is Data Science?¶
The term ‘Data Science’ has no decided upon definition. The skills that data scientists have often include:
The ability to extract usable information from data.
The ability to use that information to answer questions.
The ability to use that information to solve problems.
What’s new about Data Science?¶
The systematic use of data to inform human understanding and make decisions has existed for thousands of years. In fact, modern science largely rests on quantifying what can be said about complicated, real-world events from experimental evidence (i.e. data). So how is a Data Scientist different than a Scientist?
Recent technological advances create data at an unprecedented rate. Most mechanical devices, as well as broad categories of human behavior, are recorded and saved as data: daily movements using mobile phones, inventories of goods bought, books read (as well as which pages, and how quickly) on e-readers, etc.
With this influx of data comes a new set of problems:
Can this catalog of data be organized and understood?
Can questions be asked of such data to keep pace with the rate of collection?
What practical (computation and statistical) problems must be overcome to implement solutions to such problems?
The rate at which the worlds data grows out-paces any possibility that the individual questions and answers that scientists have traditionally engaged in will suffice. The scale of the data brings computational difficulties, while the scale and variety of the questions bring statistical difficulties different than what’s existed historically.
To meet this challenge, Data Science as a discipline involves treating data as an abstraction for which the Data Scientists attempt to solve these questions. In doing so, however, it’s important to judge new progress against the volume of scientific progress that’s come before.
Examples of Data Science Projects¶
The projects Data Scientists typically work on fall into three broad categories:
Purely descriptive summaries of a phenomenon that attempt to find either typical or unusual patterns in the data. Such projects may aim to paint a picture of a past event, assess the usability of the data for other projects, or extract interesting anecdotes from the data.
Using data to make predictions or inform future assessments of similar events. Such projects not only involve predicting future occurrences of an event, but may also assess the quality of the prediction via statistical inference.
Causal experiments attempted to understand which factors most likely caused an observed result; understanding cause and effect is necessary to distinguish correlation from causation and inform policy decisions. Such projects involve setting up experiments, such as A/B tests, or identifying “natural experiments” in historical events.
While Data Scientists usually specialize in one of these areas, a given project often touches on issues requiring understanding of all three.
Work along all of these lines result in a model, which is some compact, mathematical description of the world described by a given dataset. The output of a project may use this model in different way:
The model may descriptive, creating a picture of the phenomenon mean to inform people.
The model may be generative, creating new data by generating predictions that interact with the world.
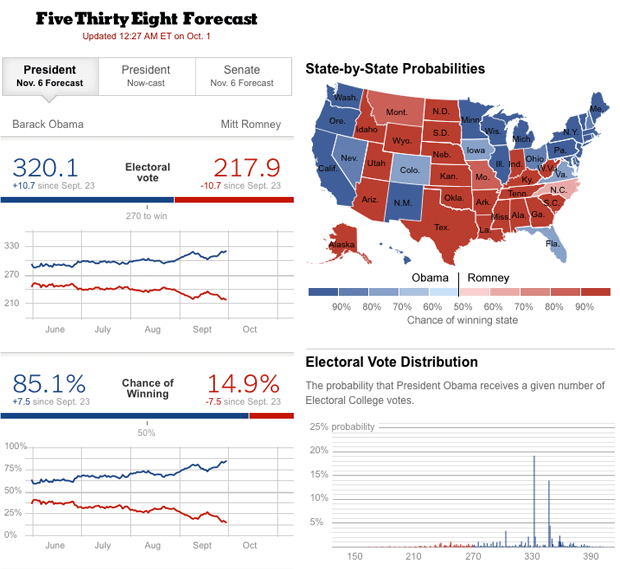
Example (Predicting Elections):
Surveying the population to understand the electorate and their political leanings. Deciding who to include in the survey involves attempting to represent the voting population using population demographics. This demographic description of voters, along with their political leanings, doesn’t just offer a prediction for an election outcome, but may also inform a campaign where to allocate resources to improve their chances of winning an election.
Example (Product Recommendations):
Data on product purchases, along with descriptions of the purchasing customers, inform a model of purchasing behaviors. Such a model not only paints a picture of current customers, but can also be used to suggest product recommendations.

Example (Face Recognition):
Photo sharing applications (Instagram, Snapchat, Google Photos) offer suggestions of likely people in a photo uploaded to their service. These suggestions are made from a model that somehow quantitatively encodes relevant portions of a face. The faces in a new photo are then encoded using the model and compared to the encodings of known friends; when two encodings (of faces) are similar, they’re assumed to belong to the same person.
In this example, the model is not used to understand a user-base, but rather finds common abstract patterns in images to discriminate between the faces of different people. This model purely offers suggestions, without any reasoning. It’s the responsibility of the Data Scientist to understand how these suggestions perform and whether the model is “good” in the context for which it’s being used.
